It often happens that many (or all) of the probability distributions of the variables in a Bayesian network are unknown, and that we want to learn these probabilities (parameters) from data (i.e., series of observations obtained by performing experiments, from the literature, or from other sources). An algorithm known as the EM (Estimation-Maximization) algorithm is particularly useful for such parametric learning, and it is the algorithm used by Hugin for learning from data. EM tries to find the model parameters (probability distribution) of the network from observed (but often not complete) data.
The EM Algorithm is well-suited for parameter estimation in batch (i.e., estimation of the parameters of conditional probability tables from a set of cases) whereas the Adaptation Algorithm is well-suited for sequential parameter update.Experience Tables are used to specify prior experience on the parameters of the conditional probability distributions. Notice that EM parameter estimation is disabled for nodes without an experience table.
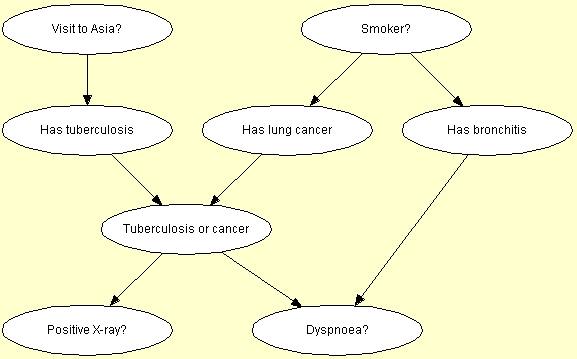
We use the example from the Experience Tables to illustrate the use of EM learning. The Bayesian network is shown in Figure 1.
Go to Chest Clinic to learn more about the domain of this network.
Figure 1: Bayesian-network representation of "Chest Clinic".
To illustrate the use of EM learning, we assume that the structure of the network is known to be as shown in Figure 1. In addition, assume that the conditional probability distribution of "Tuberculosis or cancer" given "Has tuberculosis" and "Has lung cancer" is known to be a disjunction (i.e., the child is in state yes if and only if at least one of the parents is in state yes).
We do not assume any prior knowledge on the remaining set of distributions. Thus, we set all entries of the conditional probability distributions to one except for the "Tuberculosis or cancer" node. This will turn all the probability distributions for all but the "Tuberculosis or cancer" node into uniform distributions because Hugin will normalize the values of the distribution tables if the sum of the column values differs from one. A uniform distribution signifies ignorance (i.e., we have no a priori knowledge about the probability distribution of a variable). Figure 2 shows the initial marginal probability distributions prior to parameter estimation.

Figure 2: Probability distributions after setting all values in the conditional probability tables to 1.
Now we will try to learn the probabilities from a data file
associated with this network. Press the "EM-Learning" ![]() button in
Edit Mode. When the button is pushed, the EM learning window appears.
Next, push the "Select File" button and choose a file from which the
conditional distribution probabilities are to be learned. Choose the
asia.dat file, which is located in the same
directory as the network. The first few lines of the file are shown
below
button in
Edit Mode. When the button is pushed, the EM learning window appears.
Next, push the "Select File" button and choose a file from which the
conditional distribution probabilities are to be learned. Choose the
asia.dat file, which is located in the same
directory as the network. The first few lines of the file are shown
below
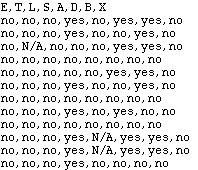
Figure 3: The first few lines of the asia.dat file.
The first line is the name of the nodes as in the network, the rest are the evidence for each experiment/observation. The evidence "N/A" means that there was on observation on the corresponding variable. After the file is selected the "OK" button appears as shown in Figure 4.
Figure 4: The EM-Learning Window
Pressing the "OK" button starts the EM-algorithm. Based on the data, the EM-algorithm computes the conditional probability distribution for each node. Figure 5 shows the new conditional probability distribution after EM-learning finishes. As can be seen from Figure 5, all the conditional probability distribution values have changed to reflect all the cases in the case file.
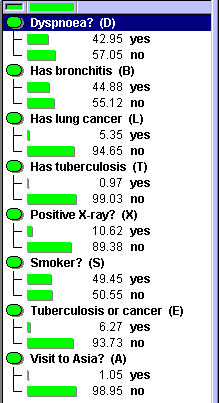
Figure 5: The estimated marginal probability distributions.
Figure 1 shows the marginal probability distributions for the network from which the set of cases was generated. Note that the probability distribution shown here is for the original Chest Clinic. network.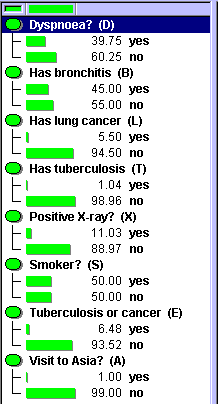
Figure 1: Marginal probability distributions of the original network
The EM algorithm can both estimate the conditional probability tables of discrete chance nodes and the conditional probability densities of continuous chance node.