Data Files
The Hugin Graphical User Interface supports saving and loading of
data files. A data file contains a set of cases as this

Figure 1: A sample data file.

Figure 2: Another sample data file.
As indicated in Figure 1, the first line is the name of the nodes
as in the network whereas each of the following lines specify a case
in which each variable is assigned a value, i.e., a set of
observations with one observation for each node. An observation may
missing in a case. A missing value is specified using N/A.
Notice that the first line of the data file always contains the
names of a (subset) of the nodes in the network. It is
important to specify the name and not the label of nodes. The name is
a unique identifier for each node. Thus, the data file in Figure 1
assumes that the network has nodes with names E, T, L, S, A , D, B and
X. This could be the node names of the network shown in Figure 3
(where node labels are shown in the nodes.)
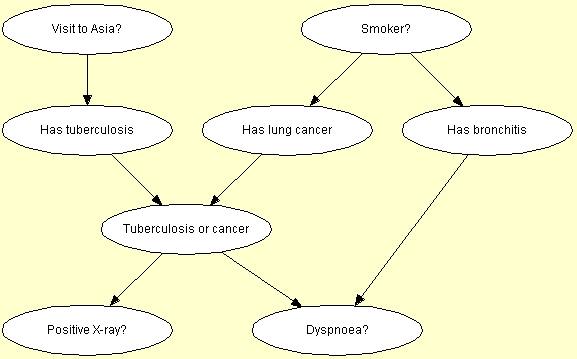
Figure 3: Bayesian-network representation of "Chest
Clinic".
Go to Chest Clinic to learn more about
the domain of this network.
See also notes on data files for OOBN EM.
The format of a data file can be described by the following grammar:
<Data file> ::= <Header> <Case>*
<Header> ::= # <Separator> <Node list> | <Node list>
<Separator> ::= , | <Empty>
<Node list> ::= <Node name> | <Node list> <Separator> <Node name>
<Case> ::= <Case count> <Separator> <Data list> | <Data list>
<Case count> ::= <Nonnegative real number>
<Data list> ::= <Data> | <Data list> <Separator> <Data>
<Data> ::= <Value> | N/A | <Empty>
<Value> ::= <State index> | <Label> | <Real number> | true | false
<State index> ::= #<Integer>
Where:
-
The <Header> must occupy a single line in the file. Likewise, each <Case> must occupy a single line.
-
If # is the first element of <Header>, then each <Case> must include a <Case count>.
-
Each <Case> must contain a <Data> item for each node specified in the
<Header>. The ith <Data> item (if it is a <Value>) in the <Data list> must
be valid for the ith node in the <Node list> of the <Header>
-
If <Data> is *, ?, or <Empty>, then the data is taken as 'missing'.
-
If <Separator> is <Empty>, then none of the separated items is allowed
to be <Empty>.
-
<Value> is as defined in Section 8.8, with the exception that <Likelihood> is not allowed.
-
<Real number> is a valid specification for CG, numbered, and interval
nodes. For numbered and interval nodes, the acceptable values are
defined by the state values of the named node.
-
<Label> is a valid specification for labeled nodes. The label (a doublequoted
string) must match a unique state label of the named node. Quotes can be omitted if the label is a single word.
-
true and false are valid specifications for boolean nodes.
Back