 |
|
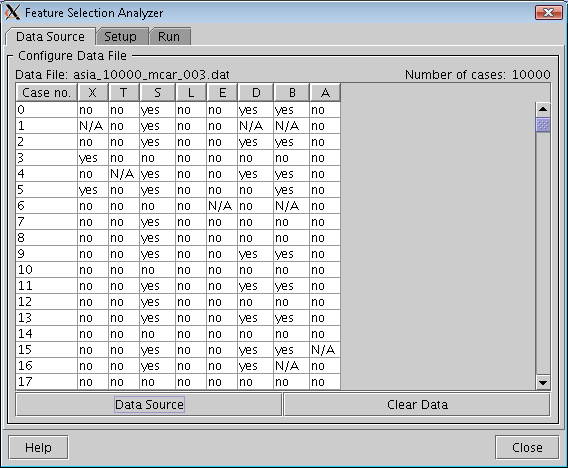
Figure 1: Data Source pane. A set of cases has been imported. |
Feature selection is an important task in the development of Bayesian networks for, for instance, classification. The HUGIN Graphical User Interface has support for feature selection through the Feature Selection Analyzer. The Feature Selection Analyzer has three steps:
Each step is described in the following sections.
|
|
Figure 1: Data Source pane. A set of cases has been imported. |
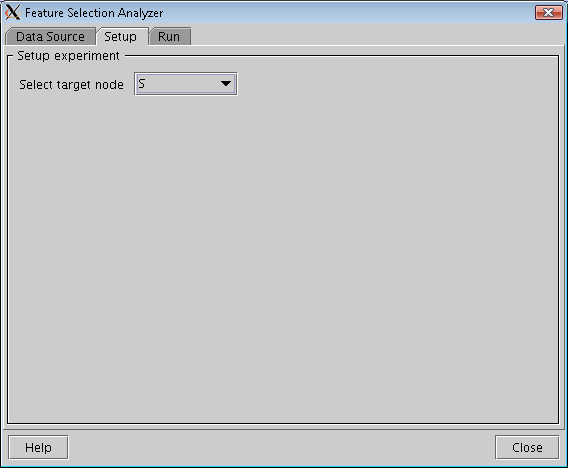
Feature selection is performed relative to a target node. The target node should be selected in this pane.
 |
|
Figure 2: Setup Pane. |
Feature selection is supported for discrete chance nodes only, i.e., the target node and the feature nodes should all be discrete chance nodes.
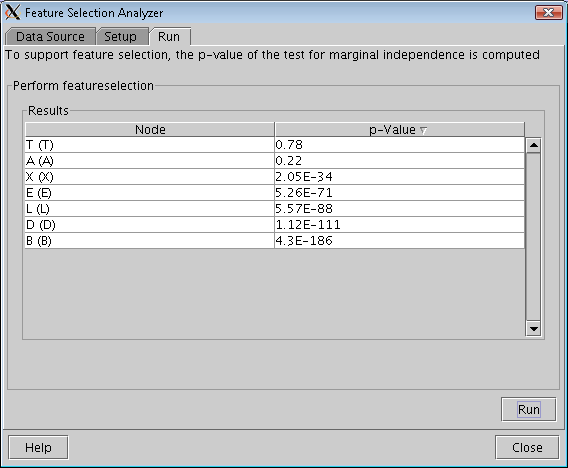
Figure 3 shows the result of feature selection on an example network and dataset.
 |
|
Figure 3: Run Pane. |
To support feature selection, the p-value of the test for marginal independence is computed. The p-value is the tail probability under the independence assumption. The higher the value the more likely the nodes are to be independent. (p is the probability of obtaining a Q value as large or larger than the Q value computed from the data under the null-hypothesis - which is the independence assumption. The Q value is a measure of the distance between the joint distribution of the feature and the target and the product of the marginal distributions of the feature and the target).
Thus, for a small value (for instance, less than a significance level alpha), the null-hypothesis that the nodes are not related is rejected and, hence, we assume the feature to be relevant for the target node.
If the user selects a set of nodes in the list, then these nodes will remain selected when the wizard is closed. This is useful for selecting the highest scoring features.